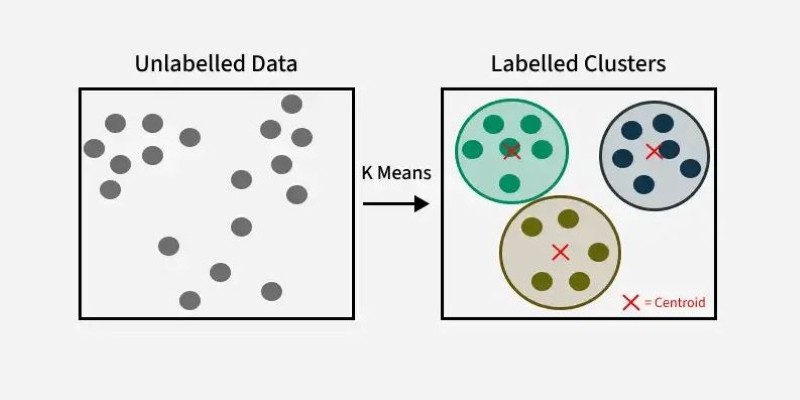
Data is everywhere, and making sense of it is no small task. K-Means clustering, a widely used machine learning algorithm, helps by grouping similar data points into clusters, revealing hidden patterns. It's a key technique in data clustering, and it is used in fields like marketing, healthcare, and image recognition to organize complex datasets efficiently. Unlike supervised learning, it requires no labeled data, making it ideal for cluster analysis in unsupervised learning.
Whether segmenting customers, detecting fraud or simplifying image processing, K-Means plays a vital role in data-driven decision-making. Understanding its mechanics allows businesses and researchers to extract meaningful insights from seemingly chaotic information.
How K-Means Clustering Works?
K-Means clustering operates as a formal procedure of splitting data into K groups. The process operates iteratively to better cluster data points. Below is a step-by-step explanation of how it works:
Choosing K Clusters: The user prescribes the number of clusters (K) prior to executing the algorithm. Careful selection of K is vital as it dictates how the data is partitioned.
Placing Initial Centroids: The algorithm picks K points at random to be the starting cluster centers, referred to as centroids.
Assigning Data Points: Each data point is affiliated with the closest centroid using a distance measure (usually Euclidean distance).
Recalculating Centroids: After data points are clustered, the centroids are recalculated to the mean position of all points in a cluster.
Repeating the Process: Repeat steps 3 and 4 until the centroids do not change much or a set number of iterations has occurred.
This strategy ensures that clusters get finer in each iteration by classifying similar data points into different clusters that are distinguished from one another. Determining the optimal value for K isn't always easy, however.
Choosing the Right Number of Clusters
Selecting the best number of clusters is a frequent problem with K-Means clustering. The most useful method to determine the ideal K is the elbow method. This is done by applying the algorithm using various K values and graphing the total sum of squared distances between data points and the centroids to which they were assigned. The location where the rate of error reduction starts to decrease more slowly—creating an "elbow" shape on the chart—is usually the ideal K.

Another approach is the silhouette score, which measures how well each data point fits within its assigned cluster versus how far it is from other clusters. A higher silhouette score suggests a better-defined clustering structure.
While these techniques help, real-world applications may require experimenting with different values of K before finding the most suitable number for accurate data clustering.
Applications of K-Means Clustering
K-Means clustering has numerous applications across different industries. Its ability to categorize large datasets quickly makes it indispensable in many fields.
Customer Segmentation
Businesses use K-Means clustering for market analysis by dividing customers into distinct groups based on purchasing habits, demographics, or online behavior. This enables companies to create targeted marketing strategies, personalized recommendations, and improved customer experiences.
Image Segmentation and Compression
K-Means clustering is widely used in image processing, particularly in segmentation and compression. By grouping pixels with similar color properties, the algorithm helps reduce the number of unique colors in an image, leading to more efficient storage and faster processing. This technique is also useful in medical imaging, where it can help detect tumors, classify tissues, or highlight anomalies in X-rays and MRI scans.
Anomaly Detection in Finance and Cybersecurity
In the financial sector, K-Means clustering plays a role in fraud detection by identifying unusual spending patterns or suspicious transactions. Since fraud typically deviates from normal transaction behavior, clustering can highlight inconsistencies that require further investigation. Similarly, in cybersecurity, K-Means helps detect network anomalies by clustering normal traffic patterns and flagging outliers that may indicate security breaches.
Gene Expression Analysis in Biology
Scientists use K-Means clustering to classify gene expression data, helping them group similar gene behaviors. This technique assists in identifying different cell types, tracking disease progression, and even categorizing genetic disorders.
These applications highlight how K-Means clustering goes beyond simple cluster analysis, offering valuable insights that drive innovation across industries.
Strengths and Limitations of K-Means Clustering
K-Means clustering is popular due to its efficiency and simplicity, but it also has some drawbacks.
Advantages
Fast and Scalable: K-Means clustering works efficiently on large datasets, making it ideal for real-time applications.
Easy to Implement: Compared to other machine learning algorithms, K-Means is straightforward and requires minimal computational resources.
Versatile: Its wide range of applications in marketing, healthcare, finance, and image processing makes it a go-to choice for many industries.
Challenges
Predefined K Value: The need to specify the number of clusters before running the algorithm can be a limitation, especially when the optimal K is unknown.
Sensitivity to Outliers: A few extreme data points can significantly shift cluster centroids, distorting group formations and reducing accuracy, making K-Means clustering sensitive to outliers in real-world datasets.
Assumption of Spherical Clusters: K-Means clustering performs well with spherical, equally-sized clusters. For irregular or overlapping clusters, methods like DBSCAN or hierarchical clustering are more suitable and provide better results.
Despite these limitations, K-Means remains a fundamental clustering technique, and strategies like K-Means++ initialization can enhance its accuracy by optimizing centroid selection.
Conclusion
K-Means clustering simplifies the complex task of organizing data, making it a fundamental machine learning algorithm in various industries. Grouping similar data points helps businesses improve marketing strategies, enhances data clustering in image processing, and even aids in fraud detection. Its speed and efficiency make it a preferred choice for large datasets, though its sensitivity to outliers and predefined cluster numbers pose challenges. Despite its limitations, K-Means remains a powerful tool for uncovering patterns in raw data. As technology evolves, clustering techniques like K-Means will continue to shape data-driven decision-making, offering valuable insights across multiple fields.